Twitterのツイートを利用
「RStudio」を「2022.07.2+576」にアップデートしたので、動作確認がてら操作してみました。
「twitteR」パッケージを使います。
ただ、GitHubのサイトを見てみると、
This is the start of a relatively leisurely deprecation period for
geoffjentry/twitteR から
「twitteR の比較的緩やかな非推奨期間の始まりです。」と、2016年頃から「rtweet」パッケージを薦めているようです。
(元々グラフ作成に興味があり「R」を使い始めたので、随所に知見不足を実感しています)
##パッケージ呼び出し
library(tidyverse)
library(twitteR)
library(RMeCab)
library(wordcloud2)
##TwitterAPI認証情報を設定
##事前にTwitterに申請しAPIのアカウントを取得しておく
consumerKey <- "wwwww"
consumerSecret <- "xxxxxx"
accessToken <- "yyyyyy"
accessSecret <- "zzzzzzz"
##TwitterAPIにログイン
options(httr_oauth_cache = TRUE)
setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)つぶやきをデータフレームに
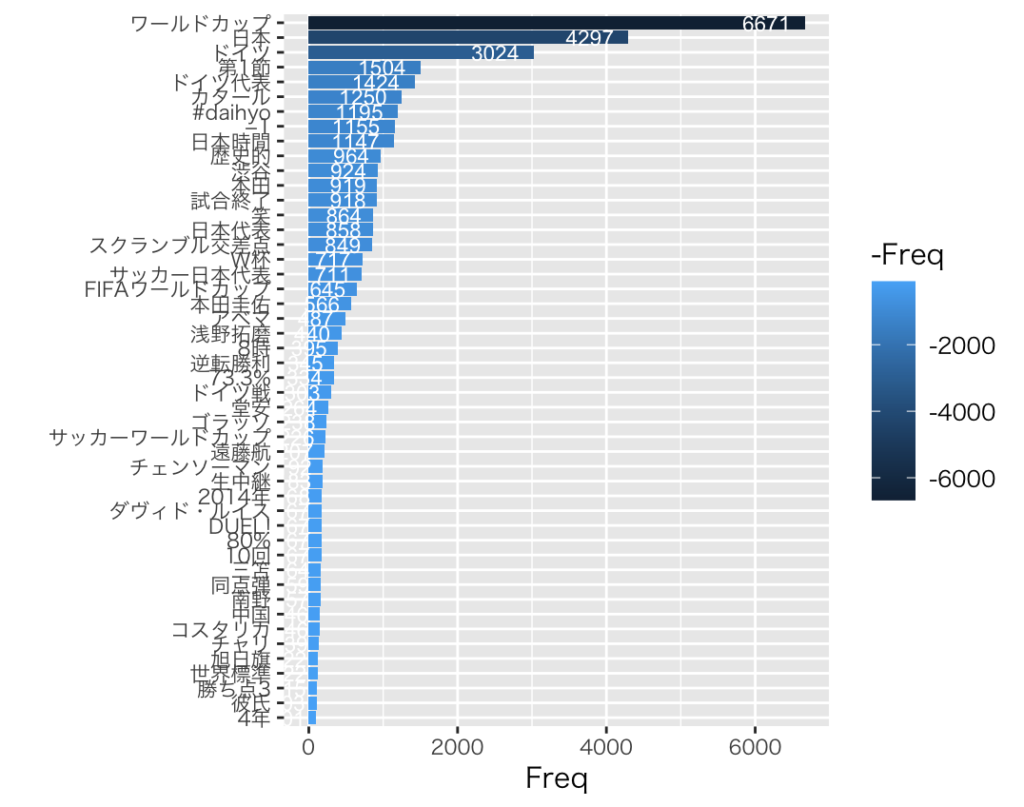
今回、検索キーワードを指定し、ツイートを10000万件取得します。
「RStudio」をアップデートしたのが2022年11月22日と「カタールW杯」開催中だったので、キーワードに「ワールドカップ」を指定しました。
##日本語ツイートを取得。ロケールも指定(日本なら"ja")
tweets1 <- searchTwitter('ワールドカップ', n = 10000,
since = "2022-11-22" , lang="ja" , locale="ja")
##データフレームに変換
tweets2 <- twListToDF(tweets2)
#確認
tweets2 %>% head()
nrow(tweets2)「twListToDF」を使い(上記)データフレームに変換し、ツイートのテキストを取り出します(下記)。
##データフレームのテキスト列だけ抽出
texts1 <- tweets2$text
##テキストとテキストの間にはブランクを入れて結合
texts2 <- paste(texts1, collapse = "") 解体素解析にRMeCabを使用
「RMeCab」で形態素解析をかけました。
##一時ファイルを作り、twfileという名前で保存
twfile <- tempfile()
write(texts2, twfile)
##形態素解析。頻度を集計
##辞書にneologdを使用
tweets3 <- RMeCabFreq(twfile, dic = "/usr/local/lib/mecab/dic/ipadic/mecab-user-dict-seed.20200910.csv.dic")
##固有名詞をピックアップ
tweets4 <- tweets3 %>% filter(Info2 %in% "固有名詞")「固有名詞」を使うことにしました。
もう少し絞り込みます。
##アルファベットと数字の単語を外したかったのですが、
##アルファベットまたは数字だけで構成する単語の正規表現が
##わからなかったので、今回は「先頭と末尾がアルファベットまたは数字」の単語を外すことにしました
tweets5 <- tweets4 %>% mutate(
teat1 = str_detect(frq3_Tw2$Term, "^[a-zA-Z_0-9]+[a-zA-Z_0-9]$")
) %>% #tibble() %>%
filter(!teat1) #「!」で「FALSE」をピックアップggplot2でトピックワードのグラフ
単語の出現回数を棒グラフで描画します。
回数(Freq)の下限を調整し、「geom_bar」を使って作成します。
##「Freq」が100以上
tw_gg1 <- tweets5$Freq >= 100 #TRUE、FALSEで返す
tw_gg2 <- tweets5[tw_gg1,]
#確認
tw_gg2 %>% arrange(-Freq) %>% head()
##ggplot2描画
par(family = "HiraKakuProN-W3")
ggplot(tw_gg2 , aes(x=reorder(Term, Freq), y=Freq))+
geom_bar(aes(y=Freq,fill=-Freq),stat="identity") +
xlab("")+
theme_gray (base_family = "HiraKakuPro-W3") +
geom_text(aes(x=reorder(Term, Freq), y=Freq, label = Freq), hjust=1.3,colour = " white", size = 3) +
theme(axis.text.x = element_text(size=8), axis.text.y = element_text(size=8)) +
coord_flip()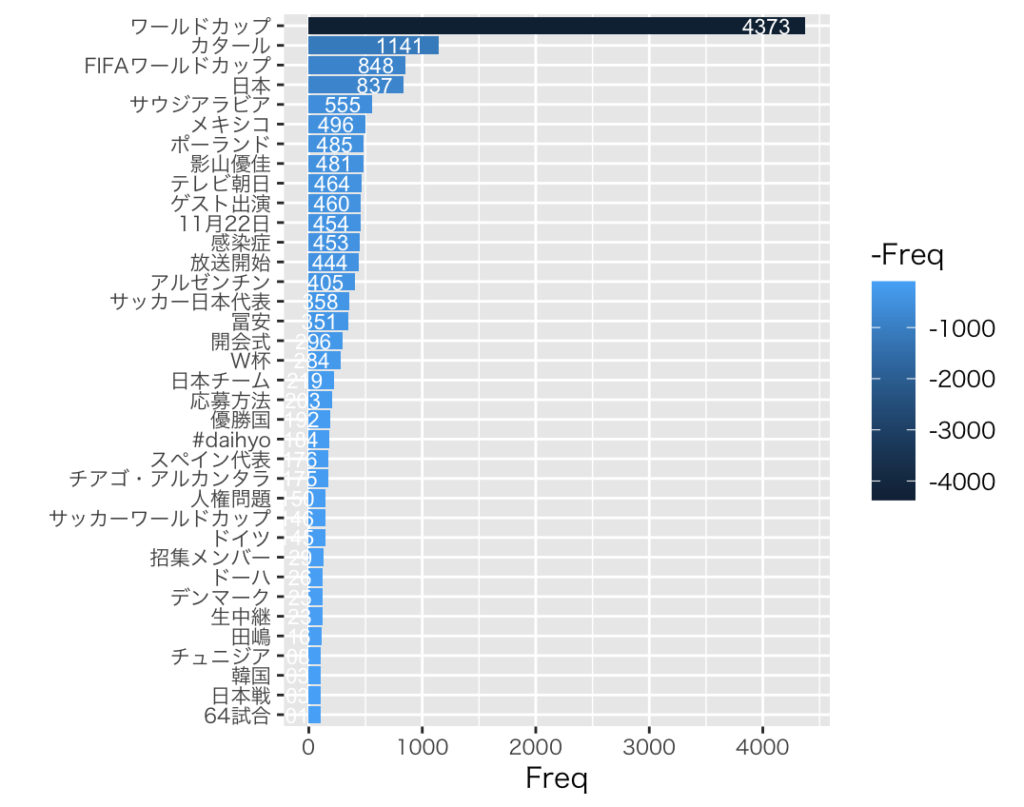
wordcloud2でワードクラウド
「wordcloud2」パッケージを使い、ワードクラウドも作成します。
##ワードクラウド作成
tw_gg2[,c(1,4)] %>%
wordcloud2(size=1.5,minSize=1,gridSize=10, shape = 'circle',
backgroundColor = 'black', color='random-light') 
W杯日本代表戦のツイートも
今回、ワードクラウドの準備をしている間に、ワールドカップ日本代表戦の日(2022年11月23日)を迎えたので、その日のツイートも取得しました。
同様に作成した棒グラフとワードクラウドです↓。